
기존의 자연어 처리 기술인 RNN과 LSTM은 순차적 처리 방식으로 인해 긴 문장에서 앞부분의 정보를 잊어버려 정확도가 떨어지는 문제가 있었다. 하지만 본 논문에서 제시한 트랜스포머 모델은 Self-Attention이라는 새로운 기법을 도입하여 이 문제를 해결했다.
Self-Attention은 문장 내 모든 단어 간의 관계를 동시에 고려하여 문맥을 더욱 정확하게 파악할 수 있게 됐으며, Multi-Head Attention을 통해 모든 단어끼리의 조합을 동시에 확인하여 더욱
또한, Self-Attention을 기반으로 한 병렬 연산이 가능해짐에 따라, 순차적 처리의 한계를 극복하고 훨씬 빠른 학습이 가능해졌다.
이로 인해 트랜스포머 모델은 NLP 분야에서 새로운 패러다임을 제시한 혁신적인 논문으로 평가된다.
https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
Attention is All you Need
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
papers.nips.cc
단어
1. 차원 인덱스 : 한 단어의 임베딩 벡터 안에서 각 요소가 차지하는 위치 번호.
1. 기존 RNN / LSTM의 한계
1. Long-term dependency problem
Transfomer 이전의 모델(RNN, LSTM) 모델들은 데이터를 앞에서부터 처리하며 각 시점의 단어들을 벡터로 바꾼 뒤 이전 시점까지의 문맥 정보가 누적된 hidden state와 현재 시점의 임베딩 된 벡터를 계산하여 현재의 hidden state를 구하는 방식으로 문장을 학습함. 결론적으로 앞에서부터 처리하기 때문에 입력된 문장의 길이가 길어질수록 앞에서 학습한 문장의 의미가 희미해지는 Long-term dependency problem가 생김 --> Self-attention & Positional Encoding을 통해 해결 가능
2. 병렬 처리의 어려움
문장을 학습할 때 각 시점의 벡터와 이전 시점를 결합하여 처리하기 때문에 한 문장당 N번의 학습이 필요함. --> Self-attetnion으로 행렬을 사용하여 병렬 처리 가능
2. Model Architecture
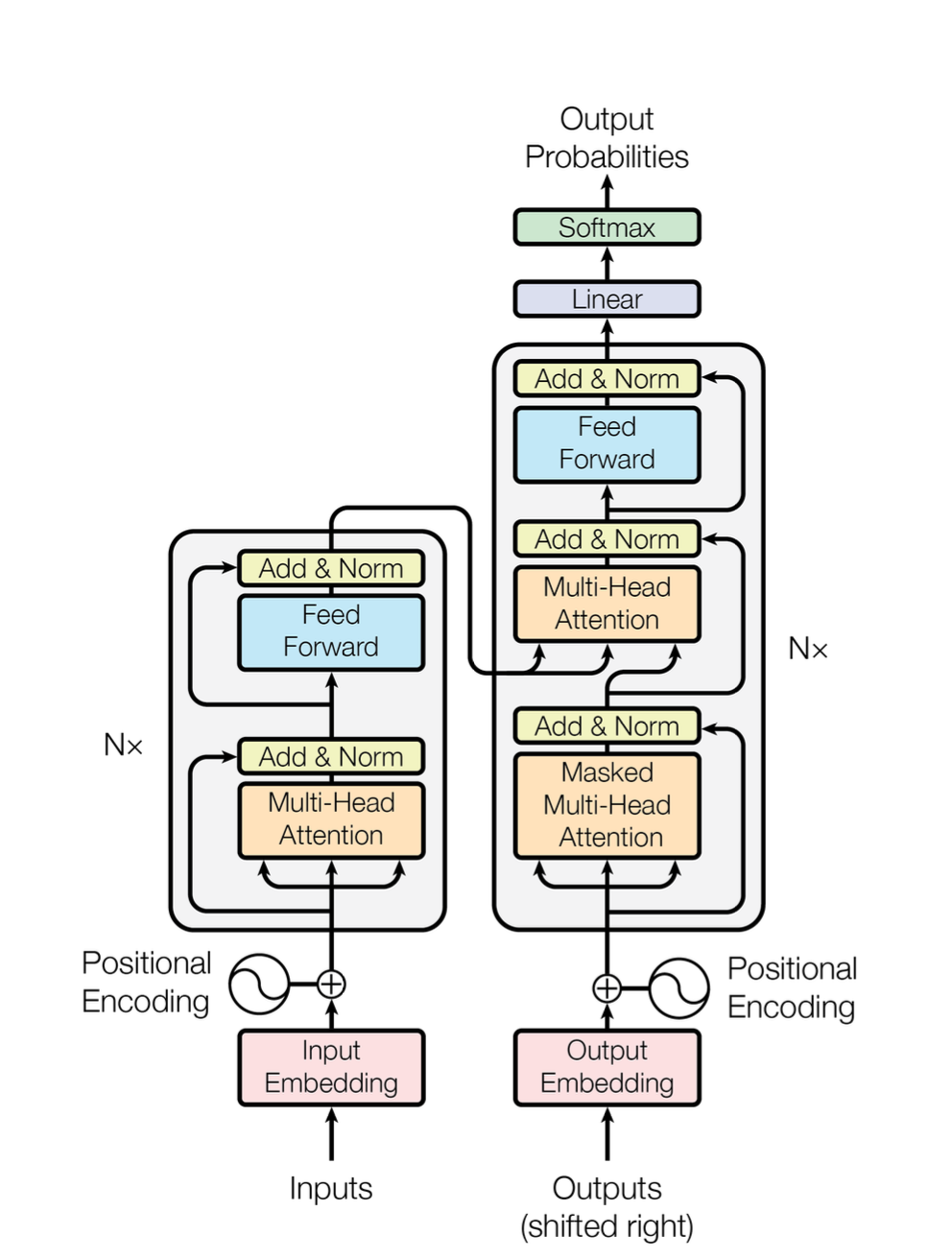
2-1. Embedding
문장을 이루는 단어들은 임베딩 과정을 거치면 512차원을 가진 벡터로 한꺼번에 변환된다. 이 과정에서 여러 문장이 들어 올 경우 1번 문장은 1행 2번 문장은 2행과 같이 각 문장은 하나의 행으로 들어가기 때문에 결과적으로 [문장수(N) * 단어 갯수 * 512]의 3차원 텐서로 변환된다. 하지만 임베딩만 된 벡터는 문장에 쓰인 단어의 순서를 구분할 수 있는 방법이 없기 때문에 단어는 같지만 순서를 다른 [I am a student // Am I a student] 이 두 문장은 의미는 다르지만 같은 문장으로 인식될 수 있다. 그래서 필요한게 Positional Encoding이다.
2-2. Positional encoding
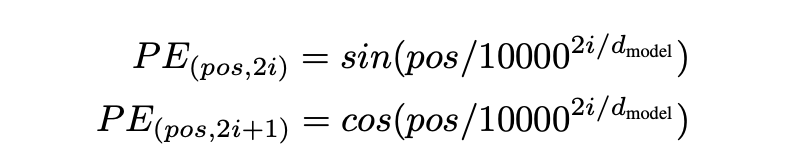
Embedding에서 봤듯이 임베딩만으로는 문장에 쓰인 단어의 순서를 알지 못한다. 그래서 단어의 위치 정보를 벡터에 더해주고자 도입한 기술이 Positional Encoding이다.
위 수식에서 pos = 단어의 위치 || i : 차원 인덱스(0~511) || d_{\text{model}} : 총 차원수(512) 를 뜻한다.
Transfomer model에서 sin/cos함수를 사용한 이유는 다음과 같다.
| 주기성 | 사인/코사인은 주기적인 함수라서, 상대 위치 간 패턴을 쉽게 잡을 수 있음 |
| 상대 거리 표현 | 어떤 위치 간의 차이가 일정하면 유사한 패턴을 가짐 (거리 유지) |
| 학습 불필요 | 이 위치 인코딩은 고정 값이라 별도로 학습할 필요 없음 (학습 파라미터 아님) |
| 멀티스케일 표현 | 높은 차원은 짧은 주기, 낮은 차원은 긴 주기를 가지므로 다양한 길이의 문맥 표현 가능 |
2-2-1. Sin/Cos함수는 주기함수이기 때문에 위치 값이 겹치면 의미도 중복되는 것 아닐까?
트랜스포머를 사용해 단어를 임베딩 했을 때 512개의 차원을 가진 벡터로 변환된다. 때문에 논문에 나온 포지셔널 인코딩 수식을 본다면 짝수 차원일때는 Sin함수를, 홀수 차원일때는 Cos함수를 사용한다. 또한 차원 인덱스(i)가 커질수록 주기는 짧아지고, d_model이 커지면 주기는 느려진다. 아래의 위쪽 그래프는 인덱스의 차원을 고정했을 때 d_model을 변화시킨 것, 아래쪽은 d_model을 고정시키고 인덱스 차원을 변화시킨 그래프이다.
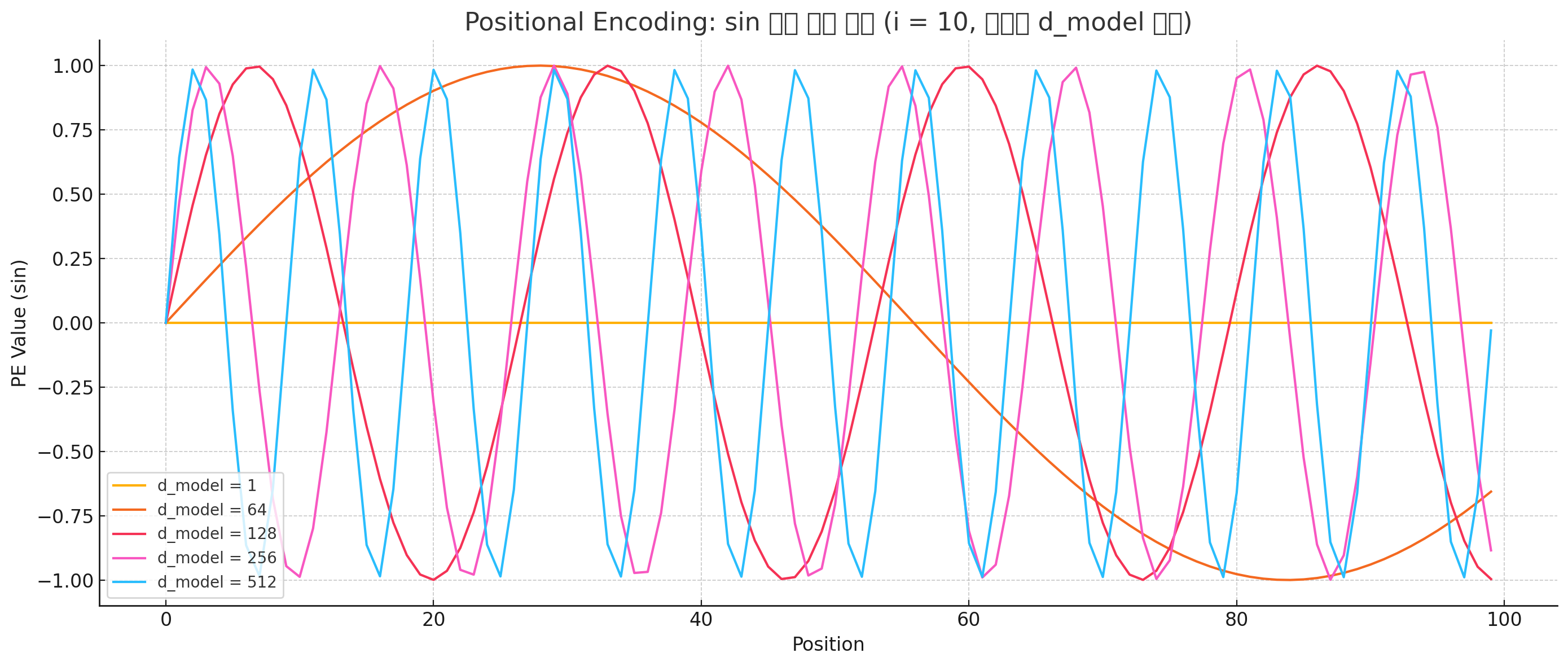
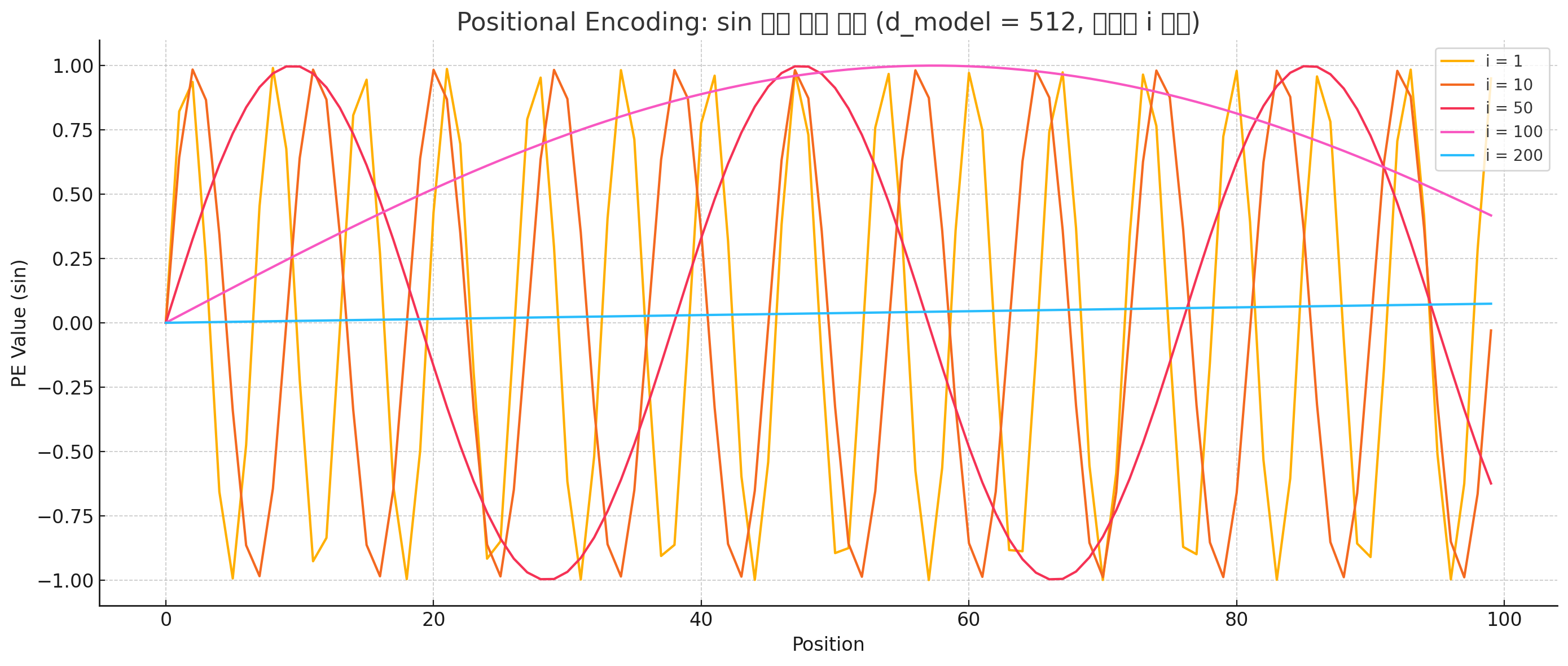
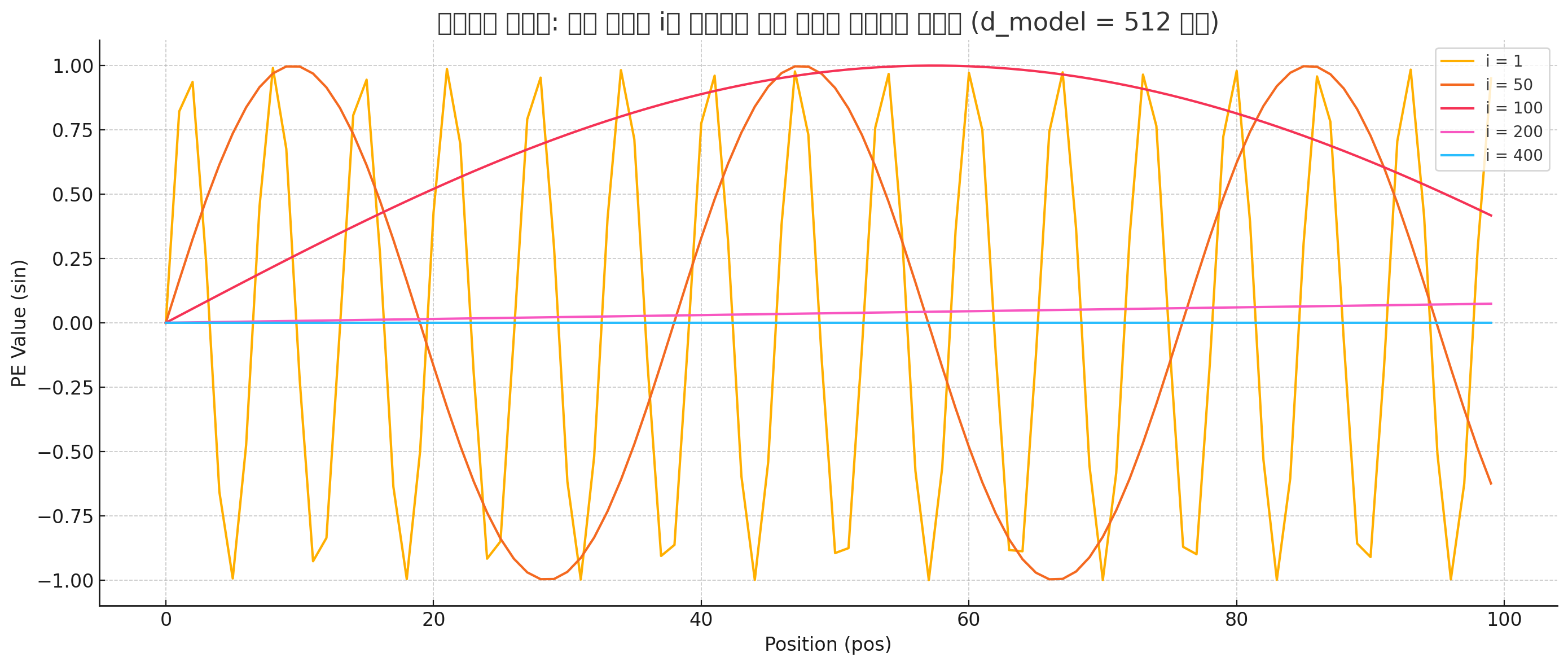
이 그래프에서도 보면 겹치는 부분이 있다. 하지만 이 부분은 일부 위치에서 서로 다른 차원의 사인값(코사인 값)이 우연히 비슷해지는 지점이 있기 때문에 그런것이다. 하지만 Positional encoding을 통해 임베딩된 단어 벡터 512개의 모든 차원에 각각 다른 주기의 위치 정보가 더해진다. 또한 단일 차원에서만 봤을때는 중복되는 부분이 있지만, 임베딩을 통해 512개의 벡터가 동시에 다르게 진동하기 때문에 위의 그래프만 봤을 땐 겹치는 값이 있는 것 처럼 보이지만 전체 벡터를 봤을 때에는 중복되거나 겹치는 경우가 거의 없다.
만약 단어의 문장의 갯수가 512개를 넘어갈 경우 가장 느리게 진동하는 차원은 한바퀴를 돌 수 있는 가능성이 생기지만 한 문장에 512개가 넘는 단어가 들어가는 경우는 극히 드물고, 넘을 경우 모델이 잘라서 처리하거나 Sliding window를 사용한다.
2-3. Encoder Stack
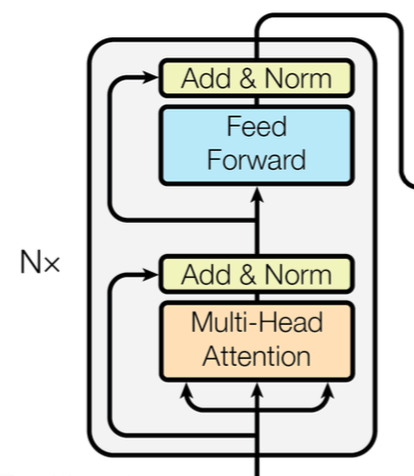
인코더 스택은 그림과 같이 이루어져 있으며, 총 6개의 동일한 인코더 블록을 쌓은 구조로 구성되어있다.
2-3-1. Multi-Head Attention
Multi Head attention에 들어가기 앞서 Attention Mechanism에 대해 알아보자.
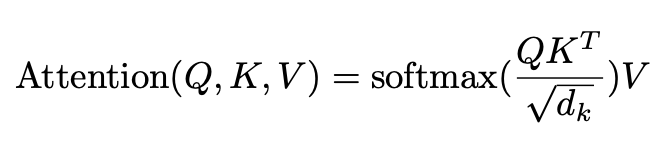
| Q(Query) | 현재 초점을 맞추고 싶은 단어의 임베딩 벡터 |
| K(key) | 다른 모든 단어들의 임베딩 벡터 |
| V(Value) | 실제로 가져올 정보 |
| d_k | Key 벡터의 차원 수 |
계산 순서
1. Q$K^{T}$ 내적 --> 4x4 행렬 생성 (4x64*64x4) // Softmax함수에 넣기 전까지는 그냥 유사도를 점수로 나타낸 행렬식에 물과함.
2. Attention score을 $\sqrt{d_{k}}$ 로 나눈 후 Softmax 함수를 적용시켜 현재 계산하는 단어와 다른 나머지 단어가 서로 얼마나 중요하게 생각하는지를 나타낸 Attention score를 생성함
- 하필 $\sqrt{d_{k}}$(차원)으로 나눈 이유 : 차원이 커질수록 내적값이 커지기 때문에 값이 터지면서 Softmax에 들어가 0, 1처럼 극단적으로 나오는 것을 방지하기 위해서. 스케일링을 해주는 것.
- 그냥 차원이 아니라 $\sqrt{d_{k}}$으로 나눈 이유 : 그냥 차원으로 나눌경우 값이 너무 작아져서 Softmax가 평평해지고 모든 단어에 비슷한 가중치를 주기때문에 Attention mechanism을 적용하는 이유가 없어지기 때문
3. Attention score와 V를 내적하여 단어와 단어가 얼마나 연관이 있는지를 알려주는 Context vector가 생성됨
2-3-2. Multi-Head Attention

Multi-Head Attention은 입력 문장을 여러 시선으로 동시에 분석할 수 있게 해주는 트랜스포머 모델의 핵심 구조이다. 앞서 봤던 어텐션 메커니즘을 8개 헤드로 나눠 병렬로 처리하고, 각 8개의 행에 해당하는 헤더들이 각자 다른 의미를 가진 어텐션스코어로 나오게된다. 이 각자 다른 의미를 가지는 어텐션 스코어를 원래의 차원인 512개로 합치는 Concat과정을 거치게 된다.
결론적으로 나오는 벡터는 (문장 수, 단어 갯수, 512)형태의 행렬로 나오게 된다. [batch_size, sequence_len, d_model]
2-3-3. Feed Forward
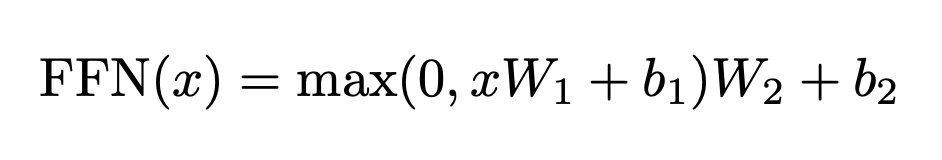
수식과 마찬가지로 xW1 + b1부분에서 W1dms 2048x512 행렬이고, x는 512x1행렬이다. 이로써 내적을 해주며 2048차원으로 정보를 ㅎ확장시켜 해석하기 때문에 훨씬 풍부하고 연관성있는 의미를 부여할 수 있다.
이후 ReLU를 적용시켜주는데, 선형 or 비선형 함수를 적용시키는 이유는 그냥 편향만 더하게 되면 정보 가공의 의미가 없고 단지 고정값만 더해주기 때문에 숫자만 무거워지게 된다. 또한 비선형 함수를 추가해준 이유는 선형 함 수를 두번이고 세번이고 계속 쌓아봤자 선형함수를 한번 거치는것과 똑같다. 즉 선형끼리만 쌓으면 쌓는 의미가 없기 때문에 ReLU를 추가해서 비선형성을 추가해준것이다.
- 왜 하필 ReLU?? : 당시 ReLU뿐만 아니라 GeLU, Sigmoid func가 있었지만 당시 가장 효율적이고 잘 알려진 비선형성 함수였고, sigmoid는 gradient vanishing 문제로 비주류로 바뀌던 상황이었다. 또한 GeLU는 있었지만 주류가 아니었다.
2-4. Decoder Stack
2-4-1. Masked Multi-Head Self-Attention

수식은 Attention과정과 동일하지만 Softmax에 들어가는 부분에 mask가 추가됐다. 논문에 다음과 같은 구문이 나온다.
We implement this inside of scaled dot-product attention by masking out (setting them to −∞) all values in the input of the softmax which correspond to illegal connections
즉 미래 단어에 대해서는 -∞로 마스킹처리하면 Softmax에 들어가면 무조건 0으로 처리되기 때문에 값을 반영하지 않게 된다.
디코더 내부에서 자기 자신을 기준으로 Attention을 계산하지만 아직 생성되지 않은 자신보다 나중에 있는 단어는 못보게 마스킹 하고 Self-attention을 수행하는것이다. 디코더는 문장을 한글자씩 생성하지만 자기 자신을 기준으로 나중에 나올 단어를 보게 되면 오픈북과 같이 정답을 미리 알게되는거랑 같다. 그렇기 때문에 Masking 처리를 해서 항상 자기보다 앞에 있는 단어만 참고하도록 Attention score를 계산한다.
2-5. Linear + Softmax
이제 딥러닝 모델이 단어를 생성하기 위해서 마지막 단계인 디코더를 6번 거쳐서 나오게 되면 각 단어 위치당 512개의 차원으로 대응된 벡투가 반환된다. 이 512차원의 벡터를 말뭉치에 있는 엄청나게 많은 단어 중 하나로 바꿔야 한다. 만약 8개의 단어를 가진 문장을 트랜스포머를 돌리면 8x512 행렬이 반환되고 말뭉치에 있는 단어 갯수가 30000이라고 했을 때 30000x512 행렬이 있다. 내적을 하기위해서는 전치된 W를 사용하기 때문에 결국 8x30000 짜리의 말뭉치에 있는 각각의 단어에 대한 중요도 분포가 담긴 벡터가 나오게 된다. 이를 Softmax에 담아 활률로 계산해서 가장 최고의 단어를 뱉어낸다
이후 한 단어를 뱉어낸 이후 다시 모델 아키텍처를 반복 순회하며 단어를 생성하게 된다. 아키텍처를 반복하면서 I am a boy라는 문장에 있는 단어를 임베딩 한 결과는 I를 임베딩 했을때와 I am을 임베딩 했을 때 I의 벡터값은 달라지게 된다.
3. Transfomer의 장점 & 한계점
장점
1. 병렬 처리 가능
기존의 RNN & LSTM은 단어를 순차적으로 처리해야 했기 때문에 병렬화가 불가능했지만 트랜스포머는 문장을 행렬로 변환하여 한번에 처리하기 때문에 병렬처리에 최적화돼있어 훈련 속도와 효율이 급상승함.
2. Long-term dependency 문제 해결
RNN 계열 모델은 문장의 길이가 길어질 수록 초반 정보가 희미해지는 Long-term dependency problem이 있었다. 하지만 트랜스포머는 Positional encoding과 Multi-head Attention을 사용하여 모든 단어를 모든 단어와 연결시켜 문장의 길이가 길어도 앞의 단어의 의미를 잃어버리지 않는다.
3. 의미 표현력 & 이해력 상승
Attention mechanism을 활용하여 각 단어가 문장 내에서 어떤 의미인지, 어떤 역할을 하는지 더욱 정확하게 파악할 수 있다.
4. 구조의 확장성과 범용성
트랜스포머 모델은 인코더-디코더 구조를 자유롭게 확장할 수 있어 BERT, GPT 등 다양한 모델로 발전할 수 있었고 자연어처리 분야 뿐만 아니라 이미지, 영상, 음성처리 분야에서까지 사용할 수 있는 모델이다.
한계점
1. 문장 길이에 따른 연산량 증가
모든 단어 쌍 사이에 관계를 전부 비교하기 때문에 O(N^2)의 시간 복잡도가 걸린다.
2. 동시 해석력의 부족함.
CNN이나 RNN처럼 순차적인 구조를 직접 가지고있지 않기 때문에 특수한 패턴을 모델링 하기에는 성능이 부족할 수 있다.이를 보완하기 위해 BERT모델이 나왔다.
3. 학습 데이터 의존도가 높고 사전 학습 없이는 성능이 낮다.
트랜스포머 모델은 파라미터수가 엄청나게 많다. 많은 파라미터를 과적합, 편향같은 문제가 안생기도록 조율하기 위해서는 파라미터를 뒷받침해줄만한 유의미한 갯수의 예시가 필요하다. 또한 문장의 복잡한 관계를 전부 데이터로만 배워야하는 구조이기 때문에 양질의 많은 데이터가 필요하다.